DeepSeek-V3 : 4 Leçons qui Prouvent que l’IA n’est plus un Jeu de Force Brute

Dans le monde de l’intelligence artificielle, la course à la puissance semblait être la seule règle : plus de données, plus de calcul, plus de dépenses. C’est dans ce paradigme de la force brute qu’un acteur inattendu, DeepSeek-V3, vient de changer les règles du jeu. Ce modèle Mixture-of-Experts (MoE) de 671 milliards de paramètres, dont 37 milliards sont activés par token, ne s’impose pas par sa taille démesurée, mais par l’intelligence de sa conception et son efficacité redoutable. Cet article explore les quatre leçons surprenantes que ce nouveau modèle nous enseigne sur l’avenir de l’IA.
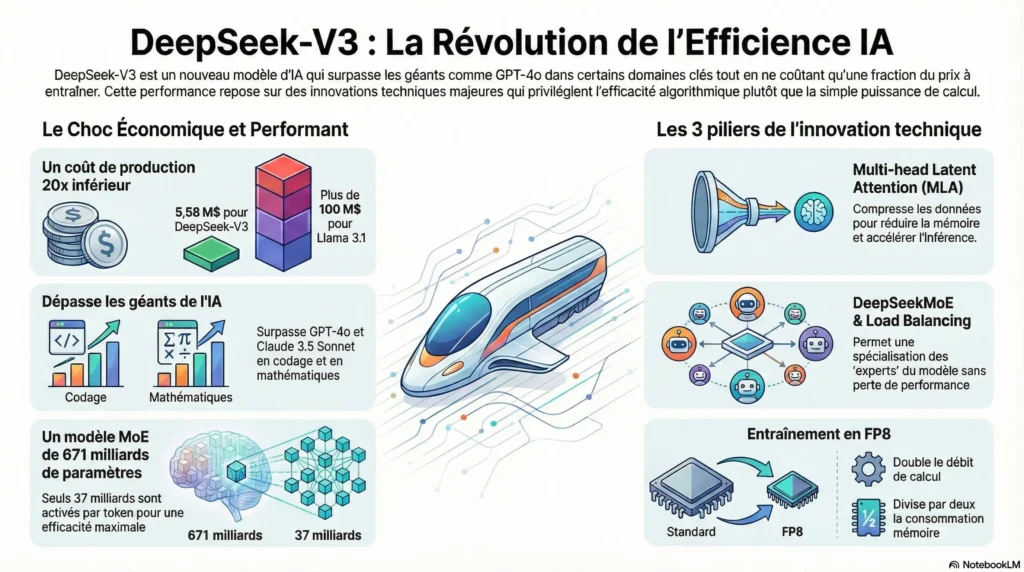
1. Le Choc Économique : Une Efficacité 20 Fois Supérieure
Le point le plus disruptif de DeepSeek-V3 est son coût de production. Alors que Meta a dépensé plus de 100 millions de dollars pour entraîner Llama 3.1, l’entraînement complet de DeepSeek-V3 n’a coûté que 5,58 millions de dollars, soit environ 2,79 millions d’heures GPU H800. Ce ratio d’efficacité de 1 pour 20 est une véritable onde de choc, dont l’annonce a contribué à une volatilité historique des actions technologiques, notamment Nvidia. Cette performance n’est pas seulement une prouesse technique ; c’est une réponse stratégique aux contraintes matérielles, un signal fort face aux restrictions d’exportation de puces. Elle prouve que le développement d’une IA de pointe n’est plus l’apanage des géants aux budgets colossaux. Ce gouffre économique n’est pas le fruit du hasard, mais la conséquence directe d’une série d’innovations architecturales audacieuses.
2. L’Innovation Prime sur la Puissance de Calcul
Cette efficacité économique n’est pas magique ; elle est le résultat direct d’innovations techniques fondamentales. DeepSeek-V3 repose sur trois piliers architecturaux qui lui permettent de faire plus avec moins :
- Multi-head Latent Attention (MLA) : Une architecture d’attention qui compresse drastiquement le « KV cache » (les clés et valeurs), un goulot d’étranglement majeur en termes de mémoire pour les grands modèles, réduisant ainsi les besoins en ressources et accélérant l’inférence.
- DeepSeekMoE & Load Balancing : Une stratégie de répartition de charge qui évite les « pertes auxiliaires » (auxiliary-loss-free), permettant une spécialisation des experts sans compromis sur la performance globale.
- Entraînement en FP8 : Pour la première fois à cette échelle, le modèle a été entraîné en précision 8-bit, ce qui a permis de doubler le débit de traitement tout en divisant par deux la consommation de mémoire par rapport aux formats traditionnels.
DeepSeek-V3 prouve que l’innovation algorithmique est devenue un levier plus puissant que la simple accumulation de puissance de calcul.
3. Plus Efficace ne Signifie Pas Moins Performant
L’idée préconçue selon laquelle « moins cher » rime avec « moins bon » est ici totalement invalidée. Plus impressionnant encore, cette efficacité ne se fait pas au détriment de la puissance. DeepSeek-V3 surpasse les titans de l’industrie comme GPT-4o et Claude 3.5 Sonnet sur plusieurs benchmarks clés. Il affiche une supériorité notable dans des domaines complexes exigeant un raisonnement de haut niveau, notamment :
- Le codage (HumanEval, Codeforces)
- Les mathématiques (MATH-500)
Ce constat est révolutionnaire : il est désormais possible d’atteindre des performances de pointe avec une fraction des ressources, ce qui ouvre la voie à des applications plus larges et plus accessibles.
4. Un Modèle d’Élite Désormais Accessible à Tous
En publiant DeepSeek-V3 sous une licence MIT permissive, ses créateurs ont fait un choix stratégique majeur. Contrairement aux modèles propriétaires jalousement gardés par les géants de la tech, cette IA de classe mondiale est désormais accessible aux chercheurs, aux startups et aux développeurs du monde entier. Cet acte n’est pas seulement philanthropique ; c’est une manœuvre stratégique brillante pour contrer les acteurs dominants. En rendant le modèle open-source, DeepSeek-V3 vise à construire un écosystème, à capitaliser sur le talent mondial pour découvrir de nouveaux usages, et à créer un avantage concurrentiel fondé non pas sur le secret, mais sur l’adoption par la communauté.
Conclusion
DeepSeek-V3 marque potentiellement la fin de l’ère du « brute force compute ». Il ne s’agit plus de savoir qui a le plus de puces graphiques, mais qui sait les utiliser le plus intelligemment. La question n’est plus de savoir si les laboratoires occidentaux peuvent rivaliser en puissance, mais s’ils peuvent réapprendre à innover sous contrainte. DeepSeek-V3 n’est pas qu’un modèle ; c’est un avertissement : l’ère de l’opulence computationnelle touche peut-être à sa fin.
Share this content:



Laisser un commentaire